
First off I want to clarify that the subject of this post is not my idea as it is something that my friend Roman Kobzarev put together for his company and I merely assisted with getting the code to work. The problem that Roman was trying to solve was that his company provided numerous PDF files that registered/paying members could download and, unfortunately, they were finding some of those files being posted to various other sites without their permission; so in an attempt to at least discourage this they wanted to stamp the PDF files with some information about the user who downloaded the file.
There are various ways in which this problem can be solved but perhaps one of the simpler approaches, and the approach outlined here, was to create an HTTP Handler which intercepted requests for any PDF files and then simply retrieve the file from SharePoint, modify it, and then send it on its way. The cool thing about this approach and the pattern shown here is that it can easily be applied to any file type which requires some user or request specific modifications applied to it.
Before I get to the actual code I want to point out one third party dependency that we used: iTextSharp. This is an open source .NET library for PDF generation and manipulation. There are many options available when looking to manipulate PDF files and in this case this one was chosen due to its cost (free). So let’s get to the code.
In terms of code there really isn’t that much which is what makes this such a nice solution. The first piece is the actual implementation of the [IHttpHandler] interface:
1using System.IO;
2using System.Web;
3using Microsoft.SharePoint;
4using iTextSharp.text;
5using iTextSharp.text.pdf;
6
7namespace Aptillon.SharePoint.PDFWatermark
8{
9 public class PDFWatermarkHttpHandler : IHttpHandler
10 {
11 public void ProcessRequest(HttpContext context)
12 {
13
14 SPFile file = SPContext.Current.Web.GetFile(context.Request.Url.ToString());
15 byte[] content = file.OpenBinary();
16 SPUser currentUser = SPContext.Current.Web.CurrentUser;
17
18 string watermark = null;
19 if (currentUser != null)
20 watermark = "This download was specially prepared for " + currentUser.Name;
21
22 if (watermark != null)
23 {
24 PdfReader pdfReader = new PdfReader(content);
25 using (MemoryStream outputStream = new MemoryStream())
26 using (PdfStamper pdfStamper = new PdfStamper(pdfReader, outputStream))
27 {
28 for (int pageIndex = 1; pageIndex <= pdfReader.NumberOfPages; pageIndex++)
29 {
30 //Rectangle class in iText represent geometric representation...
31 //in this case, rectangle object would contain page geometry
32 Rectangle pageRectangle = pdfReader.GetPageSizeWithRotation(pageIndex);
33 //PdfContentByte object contains graphics and text content of page returned by PdfStamper
34 PdfContentByte pdfData = pdfStamper.GetUnderContent(pageIndex);
35 //create font size for watermark
36 pdfData.SetFontAndSize(BaseFont.CreateFont(BaseFont.HELVETICA_BOLD, BaseFont.CP1252, BaseFont.NOT_EMBEDDED), 8);
37 //create new graphics state and assign opacity
38 PdfGState graphicsState = new PdfGState();
39 graphicsState.FillOpacity = 0.4F;
40 //set graphics state to PdfContentByte
41 pdfData.SetGState(graphicsState);
42 //indicates start of writing of text
43 pdfData.BeginText();
44 //show text as per position and rotation
45 pdfData.ShowTextAligned(Element.ALIGN_CENTER, watermark, pageRectangle.Width / 4, pageRectangle.Height / 44, 0);
46 //call endText to invalid font set
47 pdfData.EndText();
48 }
49 pdfStamper.Close();
50 content = outputStream.ToArray();
51 }
52 }
53 context.Response.ContentType = "application/pdf";
54 context.Response.BinaryWrite(content);
55 context.Response.End();
56 }
57
58 public bool IsReusable
59 {
60 get { return false; }
61 }
62 }
63}
As you can see from the previous code listing, the bulk of the code involves the actual processing of the PDF file but the core SharePoint specific piece is in the beginning of the ProcessRequest() method where we use the SPContext.Current.Web.GetFile() method to retrieve the actual file requested and then, if we can get an actual SPUser object, we create a simple message that will be added to the bottom of the PDF. I’m not going to cover what’s happening with the iTextSharp objects as the point of this article is to demonstrate the pattern which can easily be applied to other file types and not how to use iTextSharp.
To deploy this class I created an empty SharePoint 2010 project using Visual Studio 2010 and added the file to the project. I then created a new Web Application scoped Feature which I use to add the appropriate web.config settings which will register the HTTP Handler. The following screenshot shows the final project structure:
Note that I also added the iTextSharp.dll to the project and added it as an additional assembly to the package by double clicking the Package.package element and then, in the package designer, click Advanced to add additional assemblies:

Before I show the code for the Web Application Feature I first want to show what settings I set for the Feature after adding it:
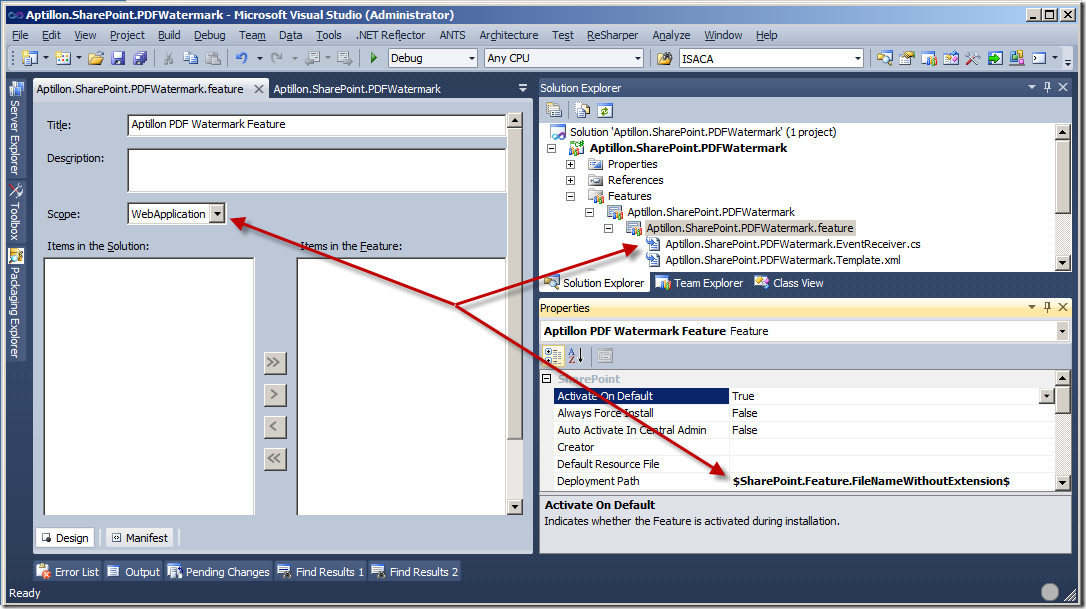
When you add a new Feature to a project it’s going to name it Feature1 and set the default scope to Web. The first thing I do is rename the Feature to something meaningful – in this case, because I know I’ll only have the one Feature I go ahead and name it the same as the project name: Aptillon.SharePoint.PDFWatermark (I always follow the same naming convention for my projects, which equate to WSP file names and Features: <Company>.SharePoint.<Something Appropriate for the Contained Functionality>). The next thing I do is change the Deployment Path property for the Feature so that it only uses the Feature name and does not prepend the project name; and finally I set the scope and title of the Feature. Now I’m ready to add my Feature activation event receiver.
The code that I want to include in the event receiver will handle the addition and removal of the web.config handler elements. I do this using the SPWebConfigModification class. Now there’s debate on whether this should be used or not; this is one of those classes where you might say (as my friend Spence Harbar puts it), “Just because you should use it doesn’t mean you can.” The simple explanation for this is that ideally you should be using this class to make web.config modifications but the reality is that this guy is fraught with issues and usually doesn’t work. That said, what I usually do is, where it makes sense, use this class to add and remove my entries but work under the premise that it will probably not work and plan on making these changes manually (or write a timer job which will do what this guy is attempting to do, but that’s out of scope of this article). So here’s the FeatureActivated() and FeatureDeactivating() methods that I use to add and remove the appropriate web.config entries which register the previously defined HTTP Handler:
1public override void FeatureActivated(SPFeatureReceiverProperties properties)
2{
3 string asmDetails = typeof(PDFWatermarkHttpHandler).AssemblyQualifiedName;
4
5 SPWebApplication webApp = properties.Feature.Parent as SPWebApplication;
6 if (webApp == null) return;
7
8 SPWebConfigModification modification = new SPWebConfigModification("add[@name=\"PDFWatermark\"]", "configuration/system.webServer/handlers");
9 modification.Value = string.Format("<add name=\"PDFWatermark\" verb=\"*\" path=\"*.pdf\" type=\"{0}\" preCondition=\"integratedMode\" />", asmDetails);
10
11 modification.Sequence = 1;
12 modification.Owner = asmDetails;
13 modification.Type = SPWebConfigModification.SPWebConfigModificationType.EnsureChildNode;
14 webApp.WebConfigModifications.Add(modification);
15
16 webApp.Update();
17 webApp.WebService.ApplyWebConfigModifications();
18}
19
20public override void FeatureDeactivating(SPFeatureReceiverProperties properties)
21{
22 string asmDetails = typeof(PDFWatermarkHttpHandler).AssemblyQualifiedName;
23
24 SPWebApplication webApp = properties.Feature.Parent as SPWebApplication;
25 if (webApp == null) return;
26
27 List<SPWebConfigModification> configModsFound = new List<SPWebConfigModification>();
28 Collection<SPWebConfigModification> modsCollection = webApp.WebConfigModifications;
29 for (int i = 0; i < modsCollection.Count; i++)
30 {
31 if (modsCollection[i].Owner == asmDetails)
32 {
33 configModsFound.Add(modsCollection[i]);
34 }
35 }
36
37 if (configModsFound.Count > 0)
38 {
39 foreach (SPWebConfigModification mod in configModsFound)
40 modsCollection.Remove(mod);
41
42 webApp.Update();
43 webApp.WebService.ApplyWebConfigModifications();
44 }
45}
With all the code in place I can deploy to my Web Application and now any time a PDF is downloaded I’ll have a nice little message displayed on the bottom of each page. Again, the intent here is to show the simplicity of the pattern and approach – with a little imagination you can easily come up with lots of other uses for this (applying security or password protection to the PDF, adding an image watermark, removing pages based on registration status thus providing “sample” versions, prefilling form fields with user data, adding a version history page, etc.). And of course all this can also be applied to other file types such as the Office files or images (though image handling would take a little more logic to ignore images not coming from document libraries).