
When troubleshooting SharePoint, you often have to dig several levels deep to discover the root of an issue. Recently one of my clients was running into an issue where the IIS application pool that was associated with their PowerPivot service application was crashing regularly at a specific time (within a minute or two) every day.
Before looking into it we immediately suspected something was up with a scheduled data refresh, just given the timing of the event and knowing that they had lots of scheduled refreshes at all sorts of times. Once we got into the system we saw that there was fortunately a very explicit error that was being logged in the event log when the application pool crashed – in this case a System.OverflowException (Value was either too large or too small for an Int16):
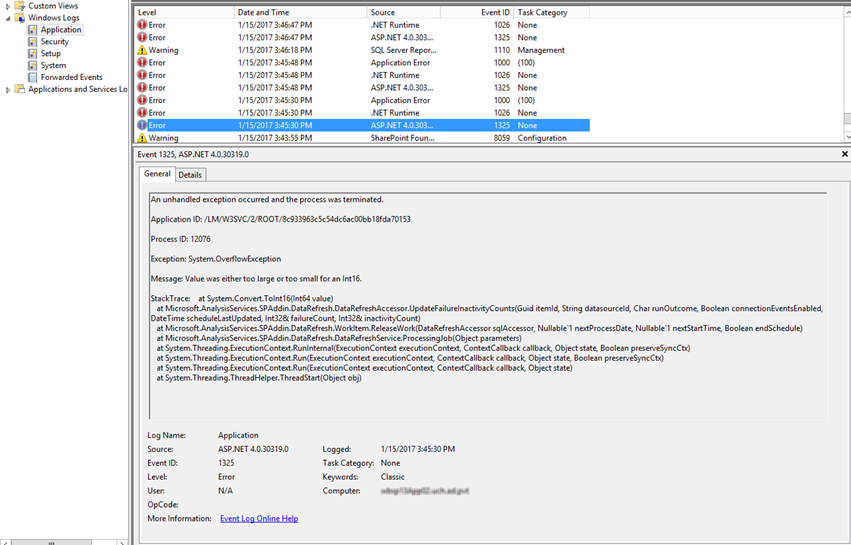
So now that we knew what the error was that caused the crash we needed to understand why it was occurring. For me, the easiest way to do that was to take a look at the assembly that was throwing the error. Using one of my favorite disassemblers I loaded up the Microsoft.AnalysisServices.SPAddin assembly which I grabbed from the GAC on the server throwing the error. Once I found the offending method I was able to see two lines in the end of the method which were attempting to convert a returned SQL parameter value to an Int16 (a number which can only be between -32767 and 32767).
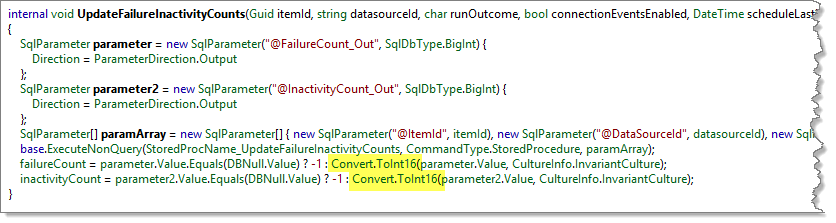
Looking more closely at the method and locating the value of the StoredProcName_UpdateFailureInactivityCounts constant I was able to see that the method called the [DataRefresh].[UpdateFailureInactivityCounts] stored procedure (pretty obvious from the constant name but always good to validate the obvious). This stored procedure updates the [DataRefresh].[WorkQ] table by incrementing the FailureCount and InactivityCount columns by one, if appropriate. As previously noted, and evident from the code snippet above, the returned value is expected to be an Int16 (value between -32767 and 32767), however, the WorkQ table and corresponding stored procedure expects the value to be an Int32 (value between -2147483647 and 2147483647).
Looking at the WorkQ table I was able to clearly see that there does in fact exist a value that is greater than what an Int16 can support (the int data type in SQL corresponds to an Int32 in .NET):
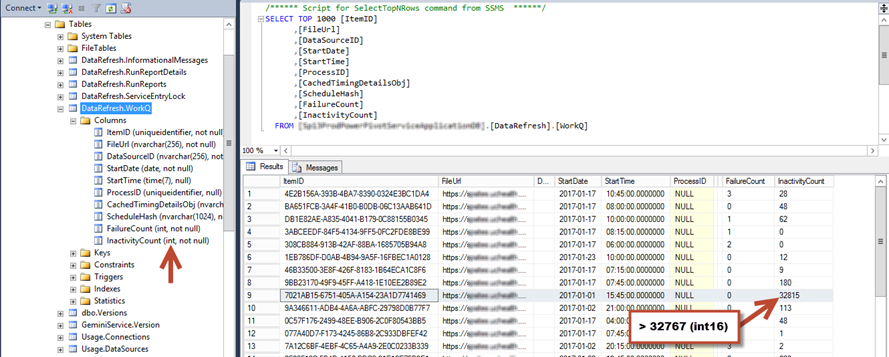
This particularly large value is what was causing the overflow error and thus what was causing the application pool to crash (we could even see in the screenshot that the start time for the refresh was 3:45pm, which is when the application pool was crashing).
So now we knew what was causing the crash, the next trick was to figure out how to correct the data to prevent the crash. Of course, I could just have hacked the database and reset the value to a lower value but that wouldn’t technically be supported and it wouldn’t prevent it from happening again. In this particular case, we noted that, though the refresh was only scheduled to occur once a month, it was actually running every day and in some cases multiple times a day (sometimes just a few, sometimes several hundred).
This frequency in which it was running over short periods of times was what was causing the inactivity count to increment but why was it running repeatedly? This is a question that, unfortunately, we never did solve. In troubleshooting the issue, we reset the data refresh schedule so that it would start on a different day (the day we happened to be working on it) and then we restarted all of the timer services on all servers (despite the timer job being set to run every minute we were seeing that the job hadn’t run for a couple of hours so a reset of the services seemed appropriate). Once this was completed on all the servers we triggered an immediate data refresh and in doing so we saw the high inactivity count value drop back to zero, thus fixing the issue that was causing the application pool to crash.
Microsoft should be able to provide a quick fix for this issue by simply adjusting the code on the database side or the SPAddin side to make sure that data types are consistent. My client has submitted this information to Microsoft to see if they will resolve it but given my past experience with such things I’m not holding my breath. Of course a better fix would be to figure out what was causing the refresh to run so often but at least if they correct the data types issue it will prevent the application pool from crashing.
We never identified the root cause of the issue because our troubleshooting steps corrected the symptoms but we’re continuing to monitor the issue to see if it occurs again and, time permitting, we’ll do some more digging to see if additional information via ULS logs and such may shed some light on the issue. In the meantime, we at least know that if the error does occur again we can get past it until we’re able to track down the root cause. I’ll update this post if we learn more.
The Business Intelligence (BI) components of SharePoint on-premises can be very complex with lots of moving pieces and oddities – if you’re having trouble with your SharePoint environment, whether it’s the business intelligence pieces or some other core components, or if you’re just wanting to get started with SharePoint BI contact us at Aptillon and we’ll help you to get moving in the right direction!